PredGAN - a deep multi-scale video prediction framework for detecting anomalies in videos
来源:引用了cvpr2018future frame prediction for anomaly detection
创新点:引入了EMD评价指标。Earth Mover’s Distance(EMD)。来判断帧是否是异常。是第一次将EMD作为评价video prediction framework的结果的评价指标。
贡献:一、提出了一个video prediction framework来检测视频中的异常。用正常事件进行训练,能够准确预测视频帧的evolution。二、引入了EMD作为评估生成帧的质量的指标,用这个标准将帧标为异常或正常。三、证明在UCSD 行人数据集和Avenue数据集上的结果达到了state-of-the-art。
Detecting Abnormality without Knowing Normality: A Two-stage Approach for Unsupervised Video Abnormal Event Detection
来源:引用了cvpr2018future frame prediction for anomaly detection
摘要:很多方法都采用了supervised setting,即需要收集正常的事件来训练,但是很少的能在不事先知道正常事件的前提下检测异常。现在的无监督方法检测剧烈局部变化的为异常,忽略了全局的时空上下文。
创新点:提出了一个新的无监督方法,包括两个阶段:首先是normality estimation stage,训练了一个自编码器,并通过自适应重建误差阈值从整个未标记的视频中全局地估计正常事件。第二,normality modeling stage,将从上个阶段估计的正常事件喂给one-class svm来建立一个refined normality model,后续可以排除异常事件并且提高异常检测的性能。
引言:现有的方法分成两类:对正常异常进行建模和仅对正常进行建模。第一类的泛化能力差,不能处理没见过的异常行为。现有的方法采用了一种supervised setting,需要人工来确定训练集,(我觉得这点考虑很好),就是说需要人来把视频分成仅包含正常的和其他的包含异常的。作者想通过unsupervised setting,实现不需要事先知道正常事件来训练一个正常模型。【什么意思,没太看懂】[8,28]两篇文章也用了这样的思路但是没有考虑全局的时空上下文。
结果:在ucsd ped1上面的结果还挺差的。
有意思的地方:在图6中,c图当一个人扔包的时候,另外一个人受到了惊吓,也被检测出来了。有意思有意思。
细节:在Normality Estimation Stage,以self-adaptive 的方式选择合适的阈值T。 通过让重建误差损失函数的inter-class variance。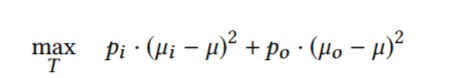
Spatio-Temporal AutoEncoder for Video Anormaly Detection
来源:ACM mm2017 作者是alibaba的【感觉是个水会】
代码地址:https://github.com/yshean/abnormal-spatiotemporal-ae
创新点:STAE 时空编码器来自动学习视频的表示,提取时间和空间特征。引入了一个weight-decreasing prediction loss来产生未来的帧。(这个loss guides 编码器更好的提取时间特征)。
引入这个weight-decreasing prediction loss是因为模型训练更容易被后续帧里面出现的新的目标影响。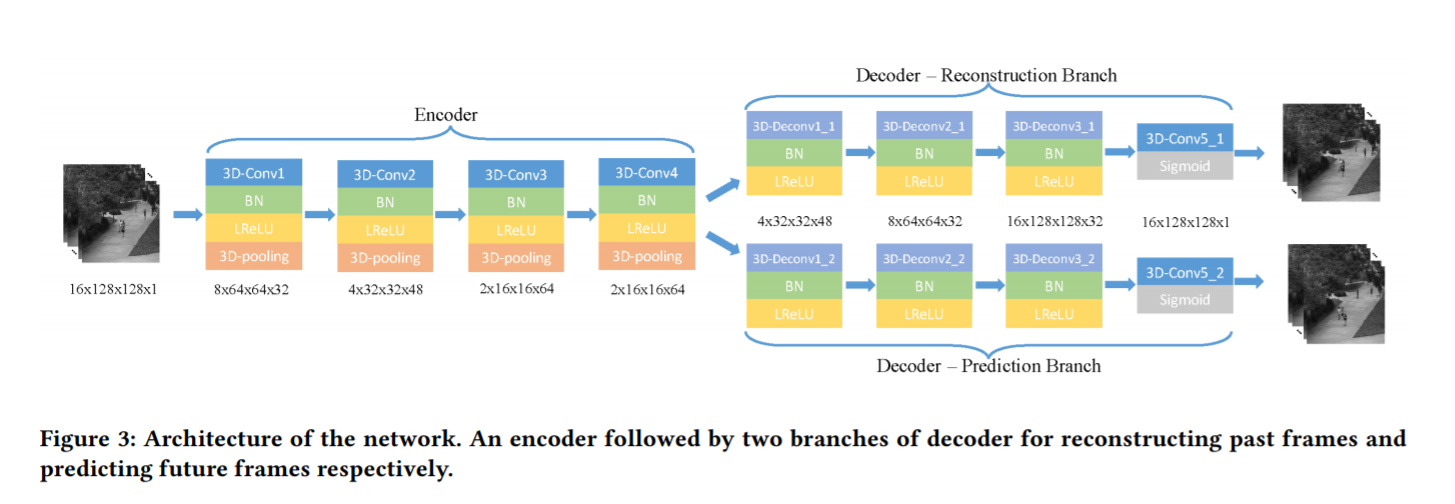
Generative Neural Networks for Anomaly Detection in Crowded Scenes
来源:期刊IEEE Transactions on Information Forensics and Security二区
代码地址:https://github.com/tianwangbuaa/VAE-for-abnormal-event-detection
创新点:S2-VAE(2是上标)。SF-VAE(F是下标)是一个浅层的生成网络生成来得到一个像Gaussian mixture 的模型来适合真实数据的分布。SC-VAE(C是下标),是个深度生成网络,利用了CNN和skip connection的优点。方法细节:SF-VAE用来从原始的样本中过滤中一些明显正常的样本,可以减少在下一个阶段的训练和测试时间。在第二个阶段,剩下的样本是先enlarged,然后进入到SC-VAE中。SC-VAE的卷积操作可以从输入中学习到hierarchical 特征和local relationship。SC-VAE比SF-VAE有更强的学习能力。
实验细节:先做预处理,先用FCN提取前景。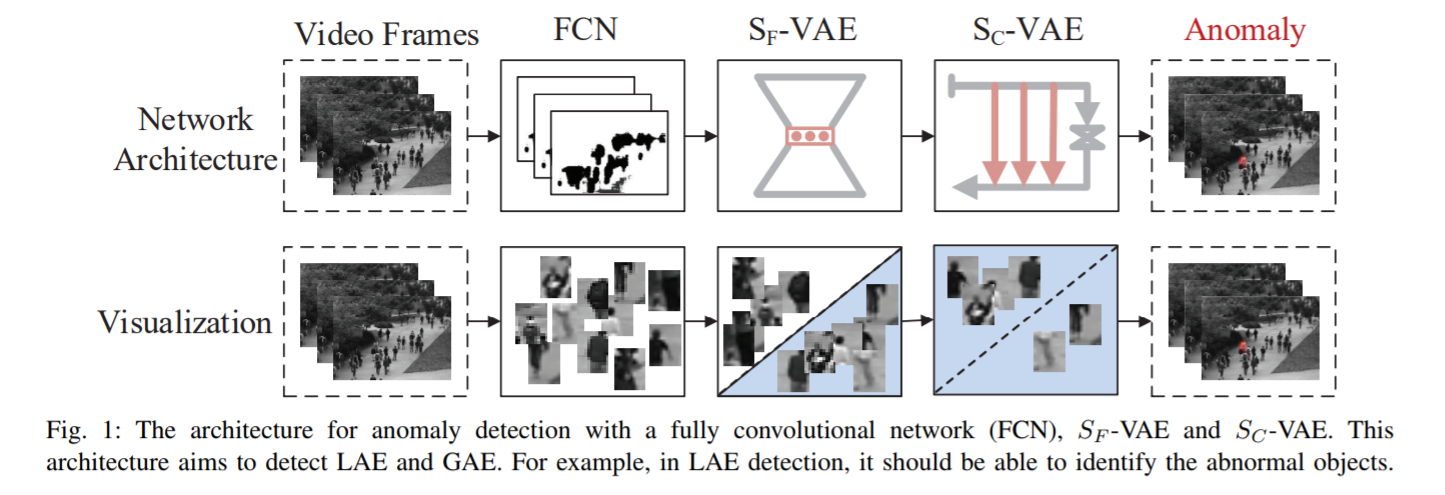
作者的一些思考?:根据模式识别和机器学习,simple Gaussian 分布没有能力来描述复杂的结构,然而,the mixture of Gaussian distribution在适应真实数据的分布上更有能力。
Detection of Unknown Anomalies in Streaming Videos with Generative Energy-based Boltzmann Models
来源:pattern recognition letters 大类3区小类4区
创新点:用了energy-based models。【这篇文章的切入点是深度置信网络】
异常检测有挑战的地方:标注数据耗费劳动力,能够利用未标注的数据就好了。第二个是定义不明确。
作者称自己的优势:大多数存在的系统能高性能的检测异常,但是不能解释为什么得到了这些检测。我们的模型可以理解场景,解释为什么产生了fault alarms,因此我们的检测结果是可解释的。我们是第一次将DBM用在视频数据中的异常检测的,也是第一次在DBM的文献中用a single model来同时聚类和重建数据的。
实验部分: A.Scene clustering 这个部分的结果和k-means 聚类进行了比较B.Scene reconstructing C.Anomaly detection 和一些无监督的异常检测系统进行比较。无监督的异常检测系统可以分为(a)无监督学习方法,包括PCA,OC-SVM和GMM(高斯混合模型).(b)CAE和ConvAE。D.Video analysis and model explanation 从图10可以看出,帧90和帧110中都有一个骑自行车的人,这个人渐行渐远,当这个人变得特别小的时候,就和别的行人颜色什么一样了,因此就解释了为什么产生了误检。
题外话:这个paper的图都好好看好有意思啊……
另外作者一直在说为什么没用RBM而用了DBM。因为在RBM中聚类模块和重建模块是分开的,所以不能保证在abstract representation和detection decision中得到一个校准(对齐?),因此我们看到的pattern maps不能反应模型真正的做的东西。而DBM可以同时训练聚类层和重建层。