2019.12.09 更新阅读笔记 来自CVPR2019《Object-centric Auto-encoders and Dummy Anomalies for Abnormal Event Detection in Video》
2019.12.10 更新阅读笔记 来自WACV2019 《Detecting Abnormal Events in Video Using Narrowed Normality Clusters》
2019.12.23 更新阅读笔记 来自ICCV2019 《Anomaly Detection in Video Sequence With Appearance-Motion Correspondence》
2020.3.26 更新阅读笔记 来自WACV2019 《Multi-timescale Trajectory Prediction for Abnormal Human Activity Detection》
2020
Multi-timescale Trajectory Prediction for Abnormal Human Activity Detection
来源:WACV2020
创新点:提出了一个multi-timescale的模型来捕获不同timescale(就翻译成时间尺度咯)的时间动态。因为不同的异常行为持续的时间不同,比如jumping和loitering。之前的研究要么是单帧要么是几个固定帧处理的。
贡献:1. 提出了一个双向(过去和将来)预测的框架,输入姿态轨迹(pose trajectory),预测不同时间尺度的姿态轨迹。2.提了一个新的数据集,包括单人、多人和群体的异常。
网络结构:

在特定的时间尺度上,将来自两个模型(过去和将来)的预测组合在一起,生成每个时刻的预测。 例如,要生成时间尺度为1的未来预测(在作者的设置中,时间尺度1表示3步的持续时间),模型首先将序列分成较小的子序列(长度为3),然后进行对将来的预测(对于下个3 步)。 将这些预测组合起来,可以得出在此时间范围内完整输入序列的未来预测。 为了获得过去的预测,反转输入序列并将其传递给过去的预测模型。 两种模型具有相同的体系结构,但训练方式不同。
对于任何时间尺度的任何时刻,该模型都会生成多个预测,因为它会在输入信号上运行滑动窗口,对这多个预测取平均就获得这个时刻的最终预测。

作者设置的时间尺度为3,5,13,25。
损失函数:损失包括两种类型,node level和layer level。有M_j个nodes的第j层的损失表示为:
新数据集:

结果:

数据集:HR-ShanghaiTech、HR-Avenue(这些是和2019CVPRLearning Regularity in Skeleton Trajectories for Anomaly Detection in Videos保持一致的。)
2019
Anomaly Detection in Video Sequence With Appearance-Motion Correspondence
链接:code
来源:ICCV2019
创新点:提出了一种深度卷积神经网络(CNN),学习常见对象外观(例如行人,背景,树木等)及其关联运动之间的对应关系。 所设计的网络由共享相同编码器的重建网络和图像翻译模型组成。
和前人的不同:和2016Hasan等人的方法不同点在于,本文的Conv-AE的输入是单帧,时间因素是通过u-net来考虑的,而Hasan等人的Conv-AE的输入要么是手工特征要么是10帧。和2017Ravanbakhsh等人不同的地方在于,本文的网络将帧翻译为光流(但是不用pix2pix GAN),同时用共享encoding flow的Conv-AE代替另外一个U-Net,而Ravanbaksh等人的方法的两个相同的CNN可能太冗余了。2018liuwen等人的方法用U-Net来预测帧,本文直接从单帧来预测光流为了确定场景外观和典型运动之间的关系。
贡献:1.设计了一个结合Conv-AE和U-Net的CNN。可端到端训练。2.在输入层之后整合了一个Inception模块【Rethinking the inception architecture for computer vision】来减少网络深度的影响。3.提出了一个patch-based 方案来估计帧级别的normality分数,减少模型输出中出现的噪声影响。
网络结构:

【生成器部分】网络包括两个处理流,第一个是通过Conv-AE学习正常事件中的共同外观空间结构,第二个是确定每个输入的pattern和它的对应的运动(由三通道的光流表示)之间的关联。U-Net中的跳层连接对于图像翻译来说是有用的因为能够直接将低层次的特征从原始域转换为编码的特征。这样的跳层连接不用在外观流中,因为网络会让输入的信息通过这些连接,就不能通过bottleneck来强调underlying的属性了。网络不用全连接层,所以(理论上)可以处理任何分辨率的图像。

【判别器部分】这个部分的网络不用在测试阶段。
损失函数:
Appearance 部分和motion部分的loss function


最后GAN网络的loss function


结果:
最后一列可借鉴,很直观。第一列是输入的帧和原始的光流,第二列是重建帧和预测的光流。

数据集:Avenue,UCSD Ped2, Subway Entrance and Exit gates, Traffic-Belleview, Traffic-Train。不用UCSD Ped1的原因是,FlowNet2不适合于距离摄像机太远的小而瘦的行人,另外就是在训练集中标注为正常的行为在测试集中却是异常。
新的评估方法:【仅考虑小块而不是整个frame】frame-level score

Object-centric Auto-encoders and Dummy Anomalies for Abnormal Event Detection in Video
来源:CVPR2019
作者:作者和Detecting Abnormal Events in Video Using Narrowed Normality Clusters【WACV2019】、Deep Appearance Features for Abnormal Behavior Detection in Video【ICIAP2017】、Unmasking the abnormal events in video【ICCV2017】为同一个团队。
创新点:第一次将异常检测当成可区分的多类分类问题(discriminative multi-class classification problem)。
贡献:1.引入了一种基于对象为中心的卷积自编码器 (object-centric convolutional auto-encoders) 的无监督特征学习框架,以编码运动和外观信息。2. 我们提出了一种基于训练样本聚类为正常簇 (normality clusters) 的监督分类方法 [即对正常行为分了类]。用一个one-versus-rest的异常事件分类器将每个正常聚类和其他的分开。
数据集:Avenue、ShanghaiTech、UCSD ped2 和 UMN
灵感来源:R. Hinami, T. Mei, and S. Satoh. Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge. In Proceedings of ICCV, pages 3639–3647, 2017. 和这篇文章的不同在于这篇文章用了ssd检测。在特征提取阶段,hinami等人在多个视觉任务上微调了Fast R-CNN模型的分类分支,以利用语义信息来检测和描述异常事件,而这篇论文用卷积自编码器来学习无监督的深度特征。
方法:整个网络分成四个阶段:目标检测阶段、特征学习阶段、训练和测试阶段。目标检测阶段——用包围框将目标切下来,然后切下来的图片送到特征学习阶段,同时计算代表运动的梯度,然后把梯度也送到特征学习阶段,见下图。特征学习阶段——将两个梯度和剪裁后的图片分别送到三个卷积自编码器中。每个隐藏层为8x8x16,最后的特征向量为3072维。训练阶段——通过构建一个context,在这个context中,正常样本中的一个子集相对另一个子集相当于虚拟异常样本,来弥补真实异常样本缺少的问题,方法就是用k-means进行聚类。测试阶段—— 每个测试样本x被k个SVM模型分类,最高的被认为是异常样本,由下式计算。


结果:frame-level AUC—-Avenue90.4 ShanghaiTech84.9 Ped2 97.8 UMN 99.6。帧率11fps(这个有点太慢了,时间用来检测了)。
可以借鉴的地方:消融实验的部分—做了这么几个实验。1.frame-level自编码器+ocsvm【one-class SVM】,说明提取对象为中心的特征和用one-versus-rest SVM有用;2. frame-level自编码器+one-versus-rest SVM,说明one-versus-rest SVM确实有用。3.预训练的ssd特征+one-versus-rest SVM,说明自编码器学习特征的重要性;4.object-centric CAE只保留外观或者运动特征,说明运动特征和外观特征的相关性。5.object-centric CAE+ocSVM,说明把异常检测当成多分类任务有用。
不足之处:检测的时候如果出现遮挡,如两人重叠,就会误报(正常被判断为异常,false positive)。
Latent Space Autoregression for Novelty Detection
来源:CVPR2019
摘要:将一个参数密度估计器(parametric density estimator)加在自编码器上。参数密度估计器通过自回归过程(autoregressive procedure)学习潜在表示的概率分布。与正常样本的重建相结合进行优化的最大似然目标,通过最小化潜在向量分布的差分熵(differential entropy),有效地充当了调节器(regularizer)。
创新点:第一次将entropy minimization的方法用在显著性检测中,之前是用在(deep neural
compression)中。
数据集:UCSD Ped2、shanghaitech
网络结构:
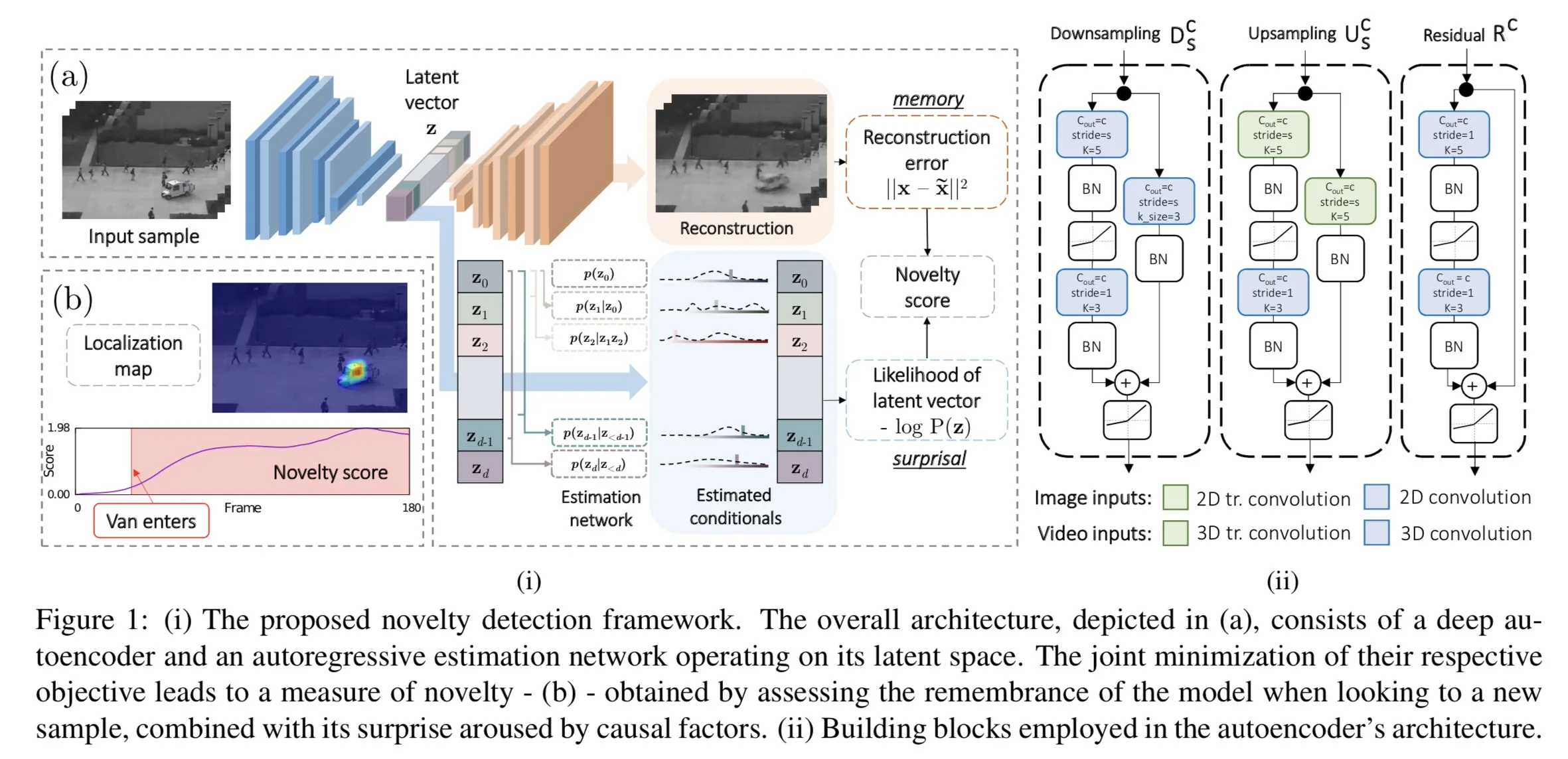
Detecting Abnormal Events in Video Using Narrowed Normality Clusters
来源:WACV2019
关于作者:作者和Deep Appearance Features for Abnormal Behavior Detection in Video【ICIAP2017】、Unmasking the abnormal events in video【ICCV2017】为同一个团队。
创新点:把异常检测当成一个检测离群点(outlier detection)的任务,分为k-means聚类和ocSVM两个阶段。
网络结构:
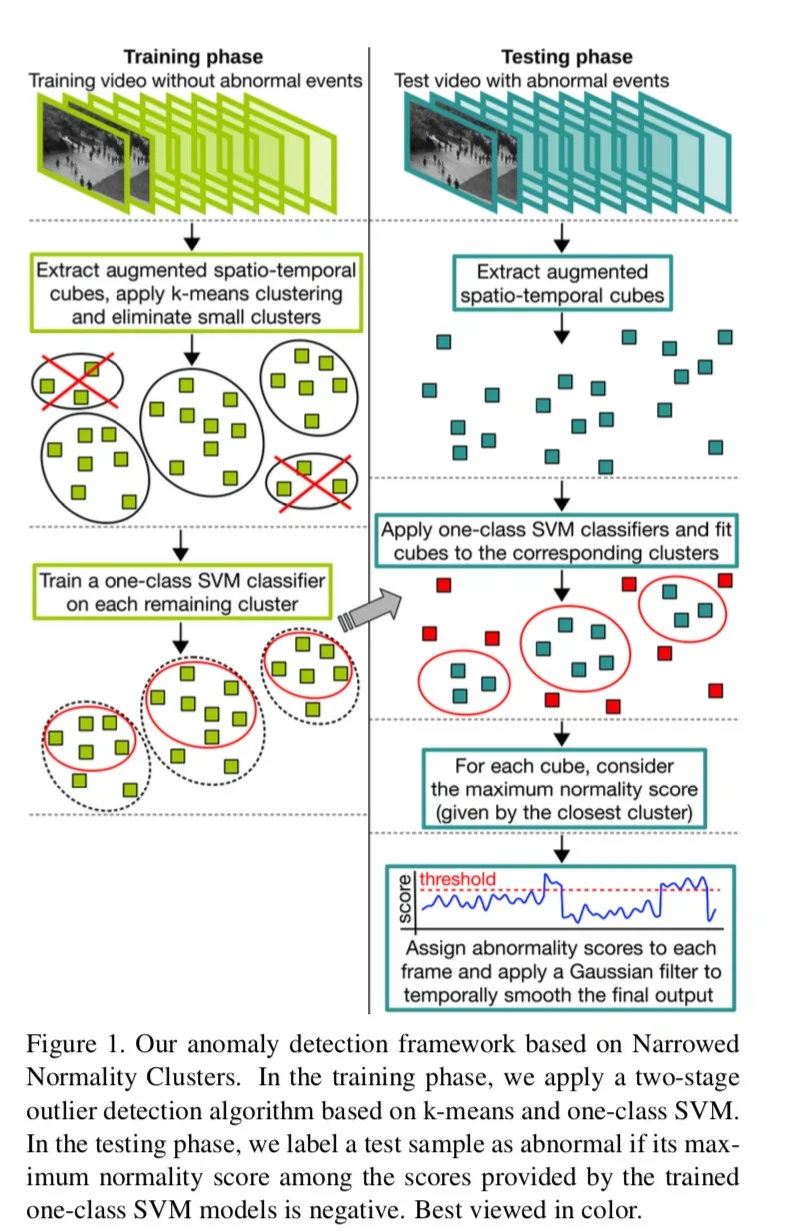
创新点:1.增强有深度外观特征的时空视频块。2.综合了两种离群点的检测方法k-means和ocSVM。3.通过学习每个聚类周围的紧密边界来缩小正常簇。
数据集:Avenue、Subway、UMN
(这篇的related work很全面哈)
方法:训练和测试的输入都是时空视频块(spatio-temporal cubes)。在训练阶段,使用k-means对提取的时空视频块进行聚类,并消除了较小的聚类作为离群值。 在其余的每个聚类上,我们训练一个ocSVM模型以除去离群的视频块。 在测试阶段,在每个ocSVM模型测试每个时空视频块,以获得一组normality得分。最大的分数(带有符号变化【这什么意思,后面第4节之前几行解释了,因为这个分数可能是负的】)作为这个块的异常分数。
特征提取阶段:对所有的数据集都这样处理,先resize成120x160,再切成不重叠的10x10小块,五帧一起作为一个视频块,维度为10x10x5。之后从每个视频块儿获得3D gradient features。如果视频在相应区域中是静态的,将消除该区域中的视频块。之后通过位置、运动方向、外观等信息增强视频块。【这个部分中提取时空视频块的代码用的是https://alliedel.github.io/anomalydetection/,2016ECCV A discriminative framework for anomaly detection in large videos】
为什么要有第二个阶段ocSVM:因为第一个阶段的k-means不能给剩下的clusters一个收紧的边界,仍然留出了很大的空间来容纳outliers。为了解决这个问题,对每个cluster都训练一个ocSVM。ocSVM学习到的边界更为tighter,因为ocSVM模型被迫将cluster中一小部分样本作为outliers。
结果:Avenue frame-level 88.9 pixel-level 94.1, 24fps。还和ICCV2017的Joint detection and recounting of abnormal events by learning deep generic knowledge进行了单独的对比,因为这个作者用的Avenue数据集去掉了5个数据集,仅用了17个。
消融实验:(未增强的)时空视频块+ocSVM;增强的时空视块+ocSVM;增强视频块+k-means+在所有k个cluster上的训练的ocSVM(没有消除小的clusters);增强视频块+k-means(消除了小的clusters)+1-NN。
误检的情况(正常被检测为异常):Avenue中两个人同步行走;一个人被遮挡;包在空中,在人扔包之前;Subway中一个奔跑的人和两个同步行走的人;UMN中一个人打开门进来或出去(对光的变化不鲁棒)。
疑惑的地方:3.1 这几个增强的方法具体是怎么操作的。
Margin Learning Embedded Prediction for Video Anomaly Detection with A Few Anomalies
来源:IJCAI2019
创新点:提出了Margin Learning Embedded Prediction (MLEP) framework for open-set supervised anomaly detection。所提出的网络有三个特征,第一,将每一帧的特征顺序输入到ConvLSTM中,更好地编码时间和空间信息。第二,把margin learning 嵌入网络结构中。有助于观测到和未观测到的异常的检测。第三,能够通过帧级别和视频级别的异常标记处理异常检测。
贡献:1.设计了MLEP来进行open-set supervised 异常检测。2.设计了一个预测框架对预测正常行为有利。3.网络可通过帧级别以及视频级别的异常标记处理异常检测。
针对问题:unet有利于异常行为的预测;传统的编码器没有足够的能力编码运动信息进而预测正常帧;卷积lstm用观测帧的历史运动信息,可能会预测异常行为。
网络结构: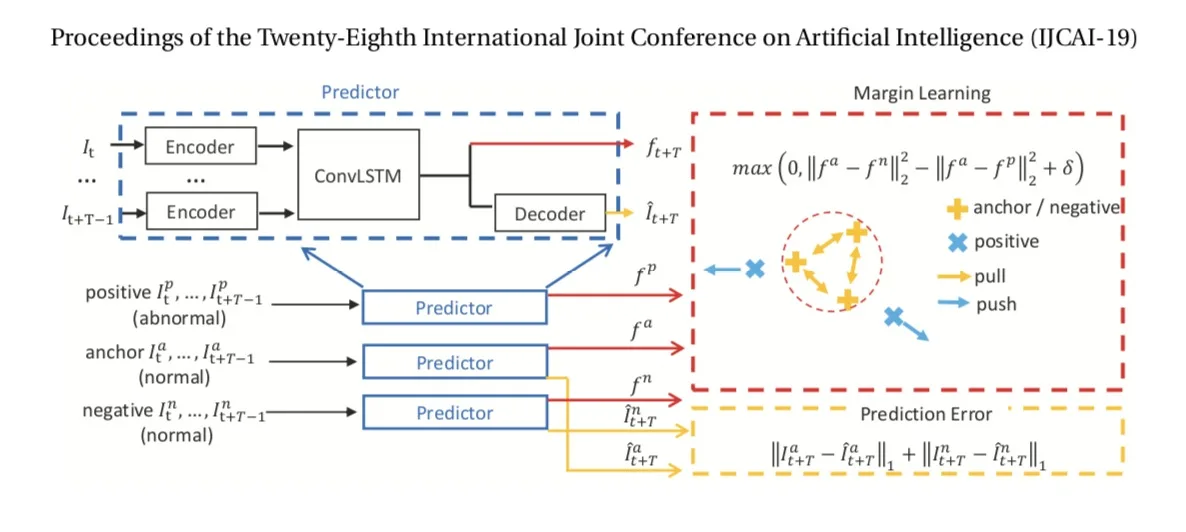

其中的margin learning模块的loss是triplet loss,灵感来自Person re- identification by multi-channel parts-based cnn with im- proved triplet loss function. 和A unified embedding for face recognition and clustering.

整个的loss就是两个loss加起来。
训练阶段:对于frame-level的标记,随机选择一个anchor,一个正样本和一个负样本来训练。对于video-level的标记,首先仅用正常数据训练一个基于预测的异常检测网络,这时不加triplet loss ,即λ=0。然后我们用训练好的模型预测正常和异常数据的正常分数。最后我们用sampled triplets来重新训练整个网络。测试阶段:仍然用PSNR来判断。越高表示越有可能是正常的。
实验细节:所有的帧resize成224X224。一个video snippet的长度是4。把测试集中的异常数据分成K折,每折仅包含一些异常事件,而不是全部的异常事件。K=10。训练的时候,把其中一折放进训练集中,然后把剩下的作为测试集。由此保证了测试集必须包含训练集没有包含的异常事件,测试集可能包含训练集中观察到的异常事件类型。为什么自己的预测的方法好也和别的方法进行了对比。用cyclegan的3个卷积层和6个残差块作为编码器,解码器用三个反卷积层。
数据集:Avenue 和shanghaitech。不用ucf crime是因为正常和异常数据的比例是均衡的,另外摄像头的角度变化,对于预测来说不理想。另外他是一个closed-set supervised异常检测,所以不进行比较。
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection
链接:code
来源:ICCV2019
作者:和CVPR2019Learning Regularity in Skeleton Trajectories for Anomaly Detection in Videos是一个团队的。
创新点:提出用一个memory module来augment 自编码器,叫做MemAE。MemAE首先从encoder获得编码,然后在训练阶段,记忆内容是更新的,测试时,学习到的记忆固定,从正常数据中选择一些记录的记忆得到重建。
针对问题:深度自编码器可能会很好地重建异常行为。比如,一些异常和正常的训练数据有相同的compositional patterns 或者decoder解码一些异常编码的时候太厉害了。
关键词: attention based memory addressing

Graph Convolutional Label Noise Cleaner: Train a Plug-and-play Action Classifier for Anomaly Detection
链接:code
来源:CVPR2019
创新点:[首次用GCN来纠正视频分析领域的label noise] a supervised learning task under noisy labels。只要清除label noise,就可以直接将完全监督的动作分类器(fully supervised action classifiers)应用于弱监督的异常检测,并最大限度地利用这些完善的分类器。为此,设计了一个图卷积网络(graph convolutional network)来校正noisy labels。基于特征相似性和时间一致性(视频的两个特性),网络将supervisory信号从高置信度的片段传播到低置信度的片段。通过这种方式,网络能够为动作分类器提供cleaned supervision。在测试阶段,我们只需要从动作分类器中获取片段预测,无需做任何后处理。
针对问题:近年来,对新兴的二元分类范式进行了一些研究,训练数据包括异常和普通视频。只有视频级别的异常标签提供。之前的工作都把弱监督异常检测问题看做是多示例学习(multiple-instance learning)。我们换了角度,看作是noise labels下的监督学习任务。噪声标签指的是异常视频中正常片段的错误注释,因为标记“异常”的视频可能包含相当多的正常片段。因此,一旦清除了噪声标签,就可以直接训练完全监督的动作分类器。
方法:两个阶段,清洁和分类。清洁阶段中,训练一个cleaner来校正classifier得到的预测噪声,并且提供了更少噪声的refined labels。在分类阶段,action classifier使用cleaned labels重新训练并且产生更可靠的预测。cleaner的主要想法是通过高可信度预测的噪声来消除低可信度预测的噪声。设计了一个GCN来建立高可信度片段和低可信度片段之间的关系。在图中,片段被抽象成顶点 (vertexes) ,异常信息通过边 (edges) 传播。测试的时候,我们不需要cleaner,而是直接获得训练snippet-wise的异常结果。
对两种类型的主流动作分类器进行了大量实验:C3D和TSN。
(我们的label noise cleaner 的目标是在高可信度注释的监督下,在图(整个视频)中对节点(视频片段)进行分类。)
Y=0(只包含正常片段的negative bag)是noiseless。而Y=1是noisy,因为部分是异常的。这就叫做one-sided label noise。
数据集:UCF-Crime Shanghai Tech UCSD-Peds

灵感来源:[Sivan Sabato and Naftali Tishby. Multi-instance learning with any hypothesis class. Journal of Machine Learning Research, 13(1):2999–3039, Oct. 2012.] MIL任务可以被视为在one-sided label noise下学习。

Learning Regularity in Skeleton Trajectories for Anomaly Detection in Videos
链接:code
来源:CVPR2019
创新点:用了dynamic skeleton features来建模人运动的正常模式。把skeletal movements分解成global body movement和local body posture。
(Message-Passing Encoder-Decoder Recurrent Neural Network)
针对问题:1.现在的方法基于像素的外观特征和运动特征,然而基于像素的特征是高维非结构化信号,对噪声敏感,它掩盖了关于场景的重要信息;另外,这些特征中呈现的冗余的信息增加了对它们进行训练的模型的负担。2.另外一个现在方法的限制是由于视觉特征和事件真实含义之间存在语义鸿沟,缺乏可解释性。
相关工作:1传统的用one-class分类的方法在处理具有各种异常类型的大规模数据的时候会获得suboptimal performance。2.基于intensity特征对外观噪声敏感。因此liu【cvpr2018】的工作用了预测的方法,但是光流提取成本高并且远离事件的语义性。
方法:【在现实的监控视频中,人体骨骼的尺度在很大程度上取决于它们的位置和动作。 对于近场中的骨架,观察到的运动主要受局部因素的影响。 同时,对于远场中的骨架,运动主要受全局运动的影响,而局部变形则大多被忽略。因此进行了分解。】

设置了一个附着在人体上的规范参考框架(称为局部框架)。全局分量被定义为原始图像帧内的局部框架中心的绝对位置,它基于骨架边界框的中心。 局部分量定义为从原始运动中减去全局分量后的残差。 它表示骨架关节相对于边界框的相对位置。 由于深度缺失,仅xy坐标不能很好地表示场景中的实际位置。 但是,骨架边界框的大小与场景中骨架的深度相关。 为了弥补这个差距,我们用骨架边界框的宽度和高度fg =(xg,yg,w,h)来扩充全局分量,并使用它们来规范化局部分量。
网络由两个 recurrent encoder-decoder network分支构成, 该模型的每个分支都具有单编码器 - 双解码器架构,具有三个RNN:编码器,重构解码器和预测解码器。网络是和[Unsupervised learning of video representations using LSTMs的工作相似。但是不同点在于,所提出的MPED-RNN不仅通过跨分支消息传递机制对每个单独组件的动态进行建模,还对它们之间的相互依赖性进行建模。用GRU代替LSTM。
输入是长度为T的skeleton segment,然后对于每个时间步长t,骨架ft分解成局部的和全局两个部分,分别送到局部和全局的编码器。

损失函数:

果然!作者用了AlphaPose来检测skeleton。
2018
real-world anomaly detection in surveillance videos
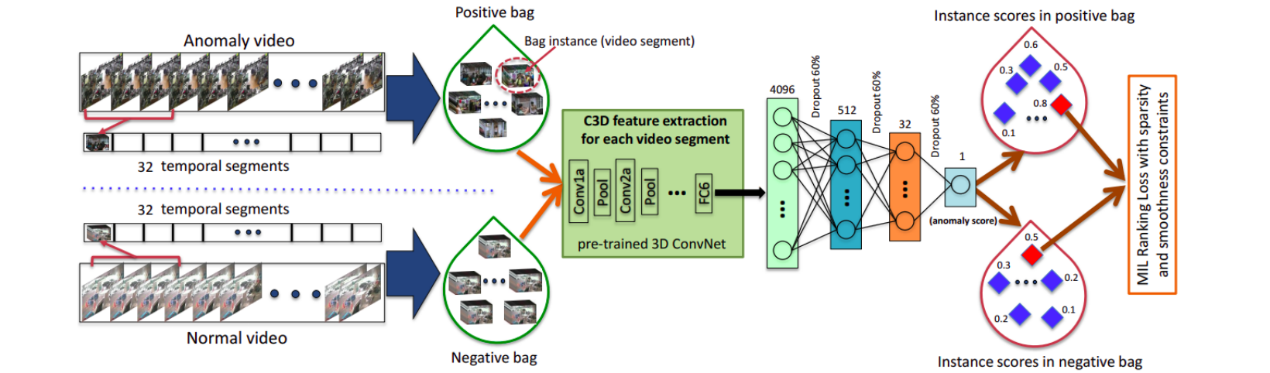
链接:code
来源:CVPR2018
使用的方法:MIL(multiple instance learning)多示例学习
方法步骤:
(1) positive(某一部分包含异常),negative(不包含异常)视频。把positive和negative视频分别分成固定数量的segments。每个视频表示为一个包,每个temporal segment表示包里的一个instance。
(2) 对video segments提取C3D features。
(3) 用一个novel ranking loss function(positive bag和negative bag中,在最高分数的instances之间计算ranking loss)来训练一个全连接神经网络。
简言之就是数据处理、提特征【提取到的特征应该是时空特征吧】、训练网络、通过得分预测是否异常。
创新点:同时利用正常和异常的视频来学习异常行为。不需要标记训练视频中的异常segments or clips(非常浪费时间),而是利用弱标记(weakly labeled)的训练视频,通过deep multiple instance ranking framework来学习异常。视频标记(异常或正常)是video-level,而不是clip-level的。我们把正常和异常的视频看作是bags,把video segments看作是instances。【采用MIL的方法引入到异常检测中来】
另外,对ranking loss function引入了sparsity和temporal smoothness constraints 来在训练中更好的定位异常。
(有新的数据集)
关键词:weakly-supervised learning,MIL
针对问题:1.其他的方法都是假设偏离正常的行为就是异常。但是这样假设是有问题的,因为把所有可能的正常行为考虑进去是不太可能的。2.正常和异常之间的界限是模糊的。在现实场景中,是否异常可能和条件的不同有关。
Baseline methods:C3D,TCNN(这两种方法在数据集上的效果很差,证明提出来的数据集非常challenging)
比较:主要和Learning temporal regularity in video sequences和Abnormal event detection at 150 fps in matlab的方法比较。
【the first to formulate the video anomaly detection problem in the context of MIL】
个人感想与总结:(采用了什么方法,达到了什么效果,还有什么不太好的地方可以改进)作者采用MIL方法,同时利用正常和异常的视频,使用提出的deep MIL ranking loss来进行异常检测。【把异常检测作为一个回归问题】
Future Frame Prediction for anomaly detection-a new baseline
链接:code
来源:CVPR2018
创新点:在视频预测框架中解决异常检测问题。除了加spatial(Appearance)约束还加了temporal(motion)约束(光流)。也用到了GAN。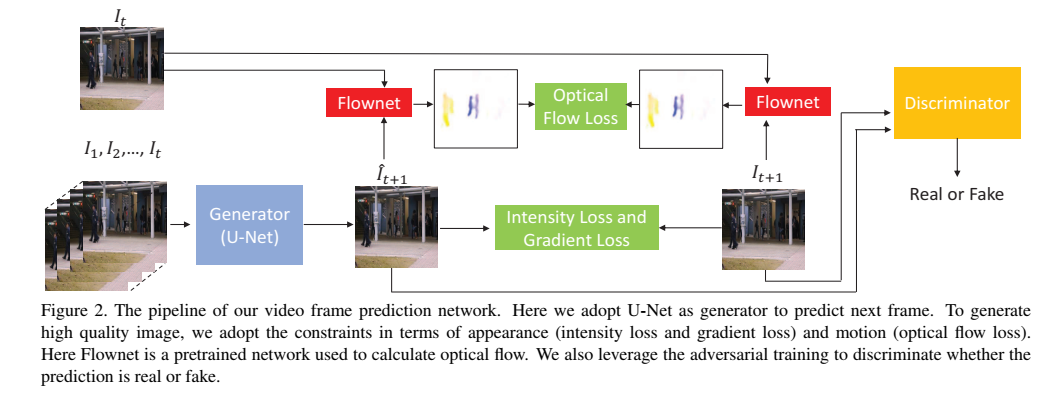
细节 :1.作者为什么用U-net?因为现在的工作进行帧预测或者图像生成的通常包含两个模块,一个编码器能够通过逐渐地降低spatial resolution来提取特征,一个解码器能够通过增加spatial resolution来恢复帧。这样的结构有梯度消失问题和信息不平衡。U-net可以抑制梯度消失的问题。
2.Intensity 为了保证在RGB空间所有像素的相似性,gradient可以锐化产生的图。
评价别人的工作:Learning temporal regularity in video sequences【16年】。Abnormal event detection at 150 FPS in MATLAB【13年】。Anomaly detection in crowded scenes【10年】。Of all these work, the idea of feature reconstruction for normal training data is a commonly used strategy.
Sparse reconstruction cost for abnormal event detection【11年】。Abnormal event detection at 150 FPS in MATLAB【13年】。hand-crafted features。
思考:我觉得作者有漏洞的地方:1.【假设正常的事件可以被很好的预测。】可是就像之前作者说自编码器那种重建的思想假设正常的事件可以以较小的误差被重建出来,但是深度神经网络的容量很高,异常事件不一定有更大的重建误差。那么在这里,正常的事件可以被很好的预测,异常的事件就不能被很好的预测吗?
2.t帧高的PSNR表示这帧很有可能是正常的。人为设置阈值来判断是正常还是异常帧。
3.没有像素级的检测
4.作者自己说 there exsits some uncertainties in normal events
5.对于作者用的gap,计算的是正常帧的平均分数和异常帧的平均分数之间的gap。【这个平均分数是不是有一点点问题,就是有没有一些正常帧其实有很小的psnr,异常帧有很大的psnr,平均是不是抹去了一些差别..重要吗。会造成一定程度的漏检吧】。而且最后加constraint的多少,看到的gap不是差很多,就差一点,不过auc还是提高了一些的。
6.在和conv-AE对比的时候,可以看到,ped1场景和avenue数据集并没有比conv-AE好太多。而且这个是平均之后的结果,真的有变好吗?
7.在最后作者用toy dataset来评估效果的时候,出现了有时正常事件的运动方向也不确定的情况。【其实就是正常的事件有时也不能很好的预测呀】
Adversarially Learned One-Class Classifier for Novelty Detection
链接:code
来源:CVPR2018
创新点:【enhance inlier,distort outlier】(1)提出来一个端到端的结构进行one-class classification。(2)几乎其他的所有基于GAN的方法在训练之后或者抛弃了生成器或者抛弃了判别器。但我们的方法更有效,能够从两个训练的模块受益。(3)用在图片或视频中。
方法:

2017
Joint detection and recounting of abnormal events by learning deep generic knowledge
来源:ICCV2017
创新点:把检测和描述视频中的异常事件联合起来。Recounting of abnormal events,就是解释为什么他们是异常的。我们把一个generic CNN model和environment-dependent anomaly detection融合起来。
(异常检测是有场景依赖性的)【动作理解动作识别的方法能不能用上?】
关键词:anomaly detector
方法:based on multi-task Fast R-CNN
- 用大量带标签的数据集【不是anomaly detection的dataset】来学习multi-task Fast R-CNN,学习到generic model。这样提取出deep features 和visual concept classification scores(同时提出的)。
- 对每个环境在这些特征和分数上学习到anomaly detectors,建模了目标环境的正常行为并且预测测试样本的异常分数。anomaly detectors和classification scores分别用来做异常行为检测和描述。{anomaly detectors有几种,NN OC-SVM KDE}
- 之后就是用以上两个学到的模型做异常检测和描述。分为四个步骤:a) detect object proposal. b) extract features.这一步由multi-task Fast R-CNN从所有的object proposal同时提语义特征和分类分数。c) classify normal/abnormal.将anomaly detector用到proposal的语义特征计算出每个proposal的异常分数,高于设定阈值的被确定为异常行为的源域。d) recount abnormal events. 异常行为的三种类型(objects,action, attributes)的visual concepts通过分类分数预测。
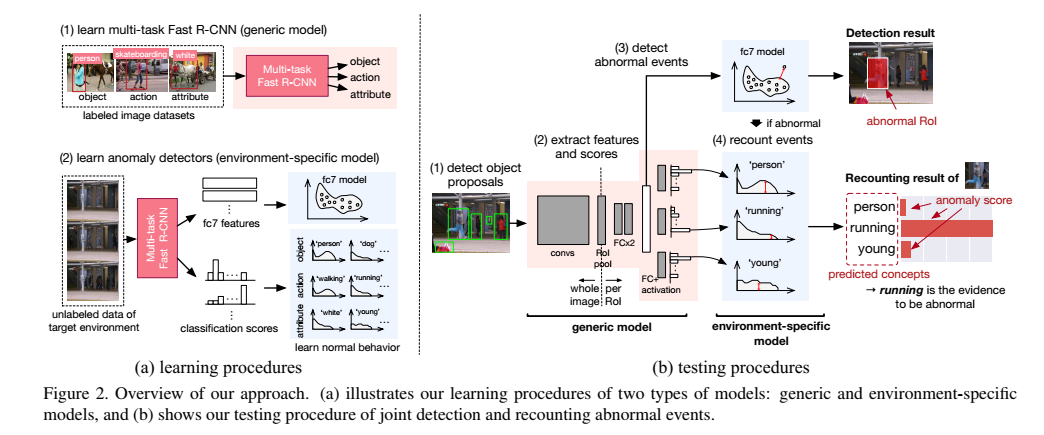 方法简言之就是提semantic特征和分类分数,特征用来判异常/正常,分类分数用来做描述,不需要使用motion features。
方法简言之就是提semantic特征和分类分数,特征用来判异常/正常,分类分数用来做描述,不需要使用motion features。
疑惑的地方:(1)The anomaly scores of each predicted concept are computed by the anomaly detector for classification scores to recount the evidence of anomaly detection.(2)(3.1)The bounding box regression was not used because it depends on the class to detect, which is not determined in abnormal event detection.
关于数据集:只选取USCD ped2和avenue进行验证,因为ped1的分辨率比较低,所以不用。关于avenue的像素级的标记有些扯淡(比较主观),比如在扔包的异常事件中,包仅仅被标记为异常,因此仅在frame-level进行评估。另外,由于avenue把moving objects看做异常,而该paper研究static objects,因此评估除去了22个clips中的5个。
结果:这个paper在avenue数据集上的auc达到89.2,ped2数据集上的auc达到90.8。FRCN的semantic feature总比HOG和SDAE特征表现好,并且不管用什么anomaly detector都比HOG和SDAE好。
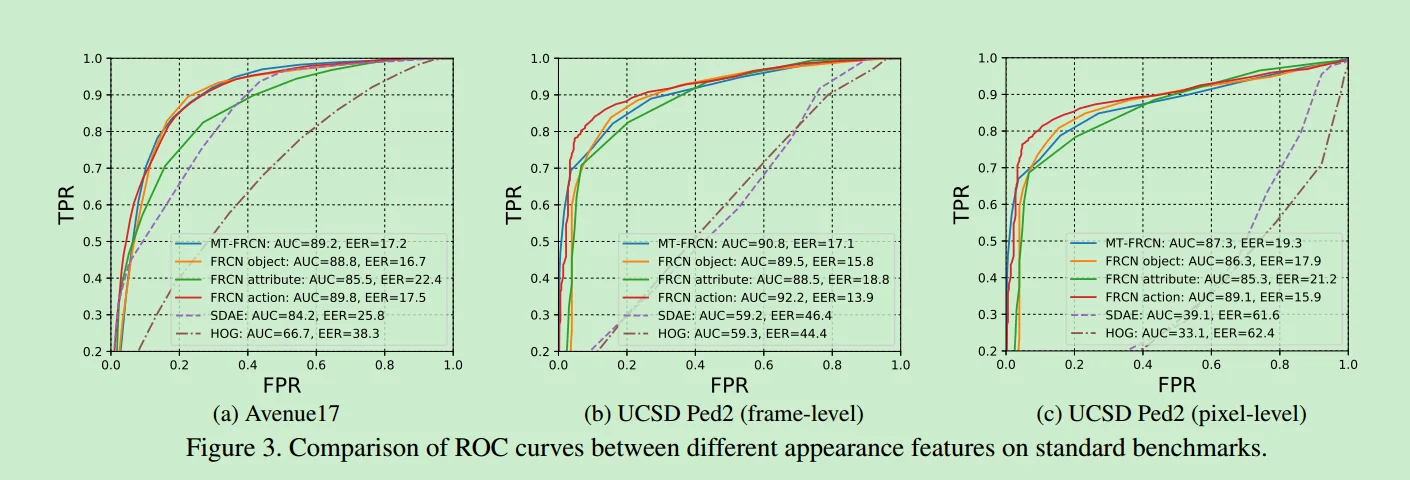
unmasking the abnormal events in video
来源:ICCV2017
创新点:不需要training sequences,我们的网络基于unmasking,是之前用来在文本文件中做授权认证的。
【the first work to apply unmasking for a computer vision task】
作者和【6 (2016)A Discriminative Framework for Anomaly Detection in Large Videos】还有一些监督的方法进行比较。【6】是主要借鉴的思想。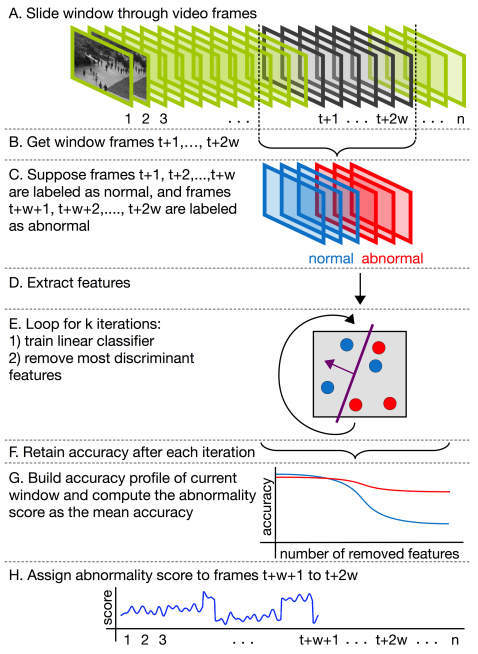
提特征,训练分类器
unmask是怎么用的:We retain the training accuracy of the classifier and repeat the training process by eliminating some of the best features.这个过程就叫做unmasking。如图中所示,After extracting motion or appearance features (step D), we apply unmasking (steps E to G) by training a classifier and removing the highly weighted features for a number of k loops.
【The unmasking technique [12] is based on testing the degradation rate of the cross-validation accuracy of learned models, as the best features are iteratively dropped from the learning process.We modify the original unmasking technique by considering the training accuracy instead of the cross-validation accuracy, in order to use this approach for online abnormal event detection in video.】
相关工作:很多方法不是完全无监督的。在此之前,唯一不用任何训练数据进行异常事件检测的是【 A Discriminative Framework for Anomaly Detection in Large Videos 2016】。作者的方法和这个很类似。但是作者的方法可以在线处理。作者的方法相当于在这个上面进行了改进。
一些说明:对10x10x5的立方块算3D gradient feature,用的是【 A Discriminative Framework for Anomaly Detection in Large Videos 2016】和【 Abnormal Event Detection at 150 FPS in MATLAB. 2013】的方法【https://github.com/alliedel/anomalyframework_python】来计算运动特征,并且不用PCA。对于外观特征,用的是VGG-f,用这个考虑的是实时性所以没有用比较深的CNN;在这儿也不对CNN进行fine-tuning,因为本文的方法不能用任何训练数据,所以只是用预训练的CNN提特征;并且,去掉全连接层,将conv5的结果作为外观特征。
对于评估指标,EER在真实的异常检测中可能是具有误导性的,所以不用这个。
结论中提到:采用了融合运动和外观特征的方法,但是没有看到大量的改善,需要进一步改进融合的方法。比如,可以用方法来在一个相关任务如action recognition上训练无监督的深度特征,然后用这些特征来同时表示运动和外观信息。
疑惑的地方:1.【related work】As the authors want to build an approach independent of temporal ordering, they create shuffles of the data by permuting the frames before running each instance of the change detection. 2.【3】2x2 spatial bins.什么是bin,为什么不直接写成4。3.【3.2】为什么假设前w帧标记为正常,后w帧标记为异常,然后训练一个分类器。这样假设有什么用?并且为什么分类器的准确率高后w帧就是异常,低的话后w帧就是正常。我觉得分类器的准确率高是异常低是正常可以这样解释:因为分类器分的准确的标志应该是将某两个特征区分度很多的类分开,如果前w是正常,后w是异常,那么分类器的准确率此时应该高,反之应该低。那么前面的假设也可以说的通了,就是相当于一个起始条件吧。
题外话:【这些作者在17年的时候还写了一篇论文:Deep Appearance Features for Abnormal Behavior Detection in Video,前面的提特征方法相同。】
abnormal event detection in videos using generative adversarial nets
来源:ICIP2017
方法:用正常的帧和对应的光流图来训练GAN,来学习正常场景的internal representation。在测试的时候把真实的数据和GAN产生的外观和运动表示比较,通过计算local 不同来检测异常区域。
从raw-pixel frames产生光流图。
a revisit of sparse coding based anomaly detection in stacked RNN framework
链接:code
来源:ICCV2017
摘要:提出了TSC(Temporally-coherent sparse coding),enforce 相似的相邻帧用相似的重建系数编码。之后用srnn映射TSC,方便了参数优化加速了异常预测。用sRNN同时学习所有参数,能够避免TSC的non-trivial的超参数选择。另外用浅层的sRNN,重建稀疏系数可以在前向传播中推断出来,节约了计算成本。
创新点:(1)提了TSC,可映射到sRNN方便了参数优化,加速了异常预测。(2)提了新数据集。作者这个新数据集的特点是不是特意设计异常事件,而是用在不同的spots安装的摄像头采集多种角度。
【为什么提出TSC?因为基于稀疏编码的异常检测方法不考虑相邻帧之间的temporal coherence。相似的特征也可能被编为不同的稀疏编码,丢失了位置信息。为了保留相邻帧之间的相似性,提出了TSC。】主要比较的
baseline的缺点:1.基于词典学习的方法的sparse coefficients的优化非常耗时间。另外这些方法主要是基于人工特征的,对于视频表示可能不是最佳的。2.2016conv-AE基于3D ConvNet,但是之前的工作表明用双流网络分别提取外观和运动信息是视频中特征的提取的一个better solution。 而且conv-AE的输入是video cube,cube中的正常/异常帧可能会影响彼此的分类,因此需要在所有的帧上对数据集进行中心采样,计算代价大。【作者主要参考或者说关注的三篇论文:2013matlab,2010MPPCA,2011online】
行文逻辑:相关工作(2)。方法(3):【什么是基于稀疏编码的异常检测(3.1);他有什么优势和缺点(即为什么用TSC),什么是TSC,如何进行优化(3.2);如何用sRNN解读TSC(3.3);如何用sRNN学习参数(3.4);多种尺度采样的多个patch(3.5);如何测试(3.6)】。我们的数据集(4)。实验(5):【设置参数和指标(5.1),用仿真数据集测试(5.2),实际数据集测试(5.3),不同超参数的影响(5.4),运行时间(5.5)。】
方法:学习能够编码外观上的正常行为的字典,之后,为了提高在相邻帧的预测的平滑性,加上了一个temporally-coherent term。(作者说,有意思的是得到的TSC的公式可以看成是一个特殊的sRNN)。
稀疏编码的目标函数: 
第一项对应重建误差,第二项对应sparsity项,lambda平衡了sparsity和重建误差。
TSC的目标函数:

实验细节:我认为首先是通过UCF101数据集用ConvNet预训练提取空间特征(没有用运动特征,作者认为不能帮助异常预测),得到特征图,然后 partition the feature map into increasingly finer regions: 1×1, 2×2, and 4×4。然后最大池化。之后对这些不同尺度的特征学习同一个词典。
测试阶段:将对应于时间t的每块的特征喂给空间sRNN,通过一次前向传播得到αt,就可以计算出对应xt的重建误差,然后选择这帧的所有块的最大重建误差作为帧级别的重建误差,然后做归一化得到每帧的regularity score。

评估:作者有个挺好的想法,先用一个Synthesized Dataset评估自己的方法对于外观的突然变化导致的异常的表现如何。这个数据集是这样做的:从MINIST里面随意找两个数字,然后把他们放在225x225尺寸的黑背景中。然后在之后的19帧里,这两个数字随意的横向纵向运动。训练的时候用了10000个序列,对于每个测试的序列,5个连续的帧由随意插入的3x3白色的小方块随意的遮挡。测试集一共有3000个序列。如下图所示: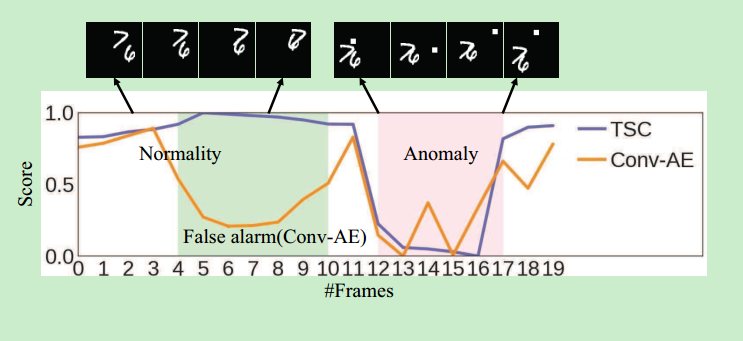
挑选数据集的一些考虑:不用subway是因为有不同的真实标记。uscd ped1更通常用在像素级别的异常检测中,本文做的是帧级别。
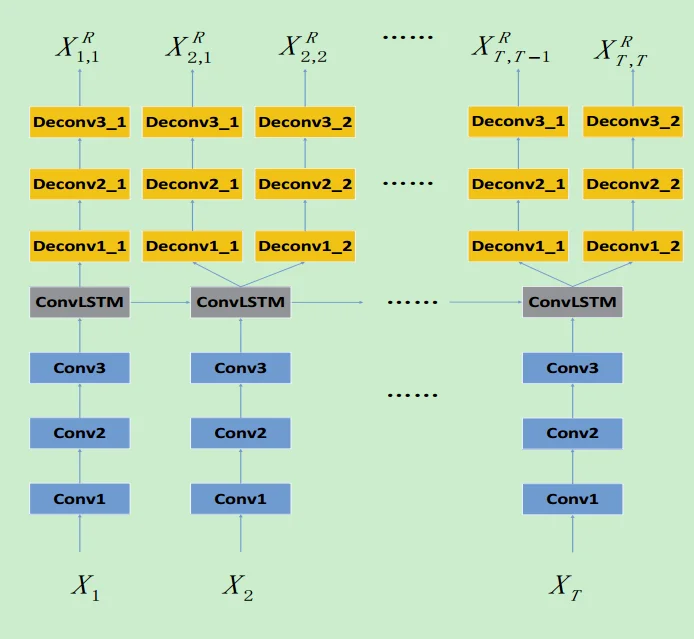
Remembering History With Convolutional LSTM for Anomaly Detection
链接:code
来源:ICME2017—IEEE International Conference on Multimedia and Expo
摘要:用CNN对每一帧进行appearance encoding,用ConvLSTM来记忆过去的帧对应于运动信息。然后把cnn和convlstm和自编码器整合起来,称为ConvLSTM-AE学习正常的外观和运动信息。
baseline的缺点:Learning temporal regularity in video sequences, in CVPR, 2016。而3D卷积不能很好的encode motion。作者的全文的关注点,或者说改进比较都是在这篇上的。
实验细节:T’越大,表示更多的信息被记住了。所以对于有频繁变化的场景,我们可以用一个更小的T‘来保证更高的准确率。
疑惑的地方:1.Learning temporal regularity in video sequences, in CVPR, 2016。In order to get a frame level anomaly prediction, it has to do the anomaly detection for multiple video clips and interpolate the degree of anomaly for each frame, which is time-consuming.2.(3.3节)In other words,we enforce the network to forget all history information every T’ frames to improve the anomaly detection accuracy。每T‘帧为单位忘掉所有的历史信息。
网络结构:
公式:
目标函数:

重建误差:

神奇之处:作者说,和2016那个convae的异常检测方法不同,我们对不同的数据集分别进行训练 ,因为异常的定义不同。所以2016那个是训练出一个通用的模型吗?
2016
Plug-and-Play CNN for Crowd Motion Analysis: An Application in Abnormal Event Detection
【the first work to employ the existing CNN models for motion representation in crowd analysis】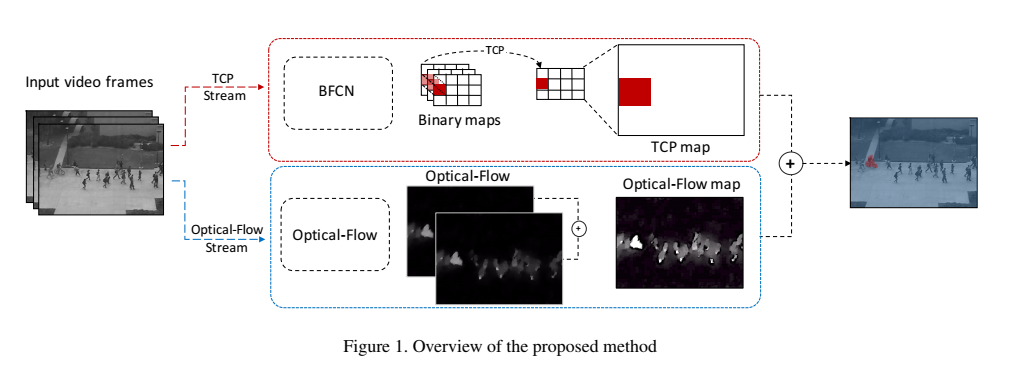
来源:WACV 2018
创新点:随着时间跟踪CNN特征的变化。通过将semantic information(从已有的CNN中得到)和low-level optical-flow结合来measure local abnormality 。不需要fine-tuning阶段。
Track the changes in the CNN features across time.
(1) 引入了一个新的Binary Quantization Layer
(2) 提出了一个Temporal CNN Pattern measure 来表示人群中的运动。
(无监督的方法比监督方法在异常检测上更好,因为标注的主观性和训练数据少)
方法步骤:

1.从输入的视频帧序列中提取CNN-based binary maps.具体来说是所有的帧输入到一个FCN,把一个binary layer 插在FCN的顶部为了把高维的特征图量化成压缩的二值模式。这个binary layer是一个卷积层,其中的权重是用一个external hashing method来初始化的。对于每个对应于FCN的感受野的patch,binary layer产生binary patterns,叫做binary map。输出的binary maps保留了最初帧的空间关系。 
(其中的FCN层用的是Alexnet)
2.用提到的CNN-based binary maps来计算Temporal CNN Pattern值。先根据binary maps来计算histograms。然后根据这些histograms计算TCP。【TCP measure 是用来表示人群的运动的motion representation】
{实验中TCP measure的分数来衡量是否异常,公式如下}

3.将TCP值和低层次的运动特征(光流)来找到refined motion segments。
细节:Binary Quantization Layer——–为什么用这个层,因为聚类高维的特征图需要很大的成本,另外就是需要事先知道聚类中心,用hashing方法聚类高维特征得到小的binary codes是一种解决方法,24位的binary code可以address 2的24次方聚类中心,另外binary map可以简单表示为三通道的RGB图。我感觉这层的实现就是 ,再通过sigmoid函数,最后通过阈值0.5编码为0或者1。
,再通过sigmoid函数,最后通过阈值0.5编码为0或者1。
Iterative Quantization Hashing(ITQ)——-是所用的hashing方法,训练这个ITQ是所提方法中的唯一训练成本,只需要在训练数据的子集中做一次,用从ITQ学到的weights来建立BQL层。
关键词:BFCN、TCP
learning temporal regularity in video sequences
来源:CVPR2016
创新点:学习正常行为模式用非常有限的监督。两种方法:第一种用传统的人工时空局部特征,并在这些特征上面学习一个全连接的自编码器,但是这些特征可能对于学习正常不是最优的;第二种建立一个fully convolutional feed-forward autoencoder来学习局部特征和分类,是一个端到端的框架。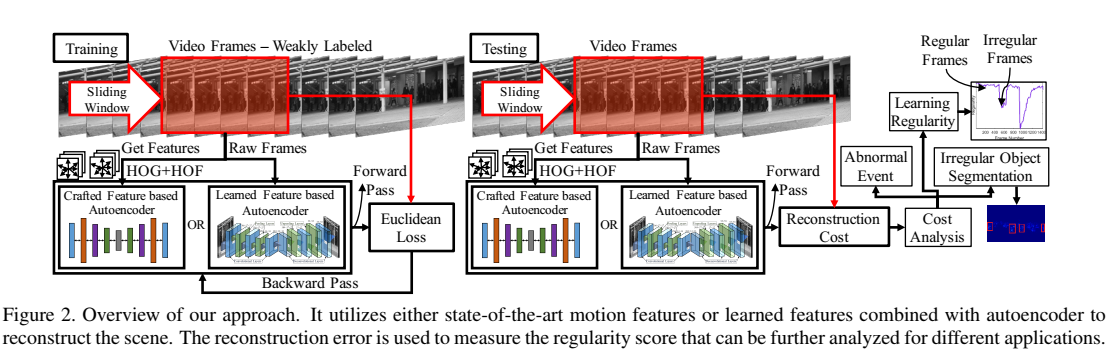 第一种Learning Motions on Handcrafted Features。首先用HOG和HOF作为时空appearance feature 描述子。为了提取HOG和HOF特征以及轨迹信息,用的是improved trajectory(IT)features。编码器的输入是204维的HOG+HOF特征。目标函数:
第一种Learning Motions on Handcrafted Features。首先用HOG和HOF作为时空appearance feature 描述子。为了提取HOG和HOF特征以及轨迹信息,用的是improved trajectory(IT)features。编码器的输入是204维的HOG+HOF特征。目标函数:

xi是特征。
第二种是全卷积自编码器,输入是temporal cuboid。【因为自编码器的参数数量太大,所以需要大量的数据。】因此做了这样的事:用不同的skipping strides连接帧来建立T-sized input cuboid。目标函数: 
Xi是第i个cuboid。
baseline的缺点: “Abnormal event detection at 150 fps in matlab,” in ICCV, 2013; “Online detection of unusual events in videos via dynamic sparse coding,” in CVPR,2011; “Sparse Reconstruction Cost for Abnormal Event Detection,” in CVPR, 2011。稀疏编码的优化计算代价大。词袋不能保留单词的时空结构并且需要单词数的先验信息。
有意思的地方:1.4.4节predicting the Regular Past and the Future。给中间的帧,能预测near过去的和未来的帧。(预测过去有什么用?)
2.用了最大池化,空间信息就丢失了,所以在反卷积网络中用了unpooling。
3.作者在4.1节画了这样的曲线:蓝色是表示在单一的数据集上训练的,红色表示在所有的数据集上训练的,黄色表示在除了要测试的数据集上训练的(足以表明transfer的能力) 
疑惑的地方:1.(3.1.1)ReLU is not suitable for a network that has large receptive fields for each neuron as the sum of the inputs to a neuron can become very large.2.(3.2.1)The learned filters in the deconvolutional layers serve as bases to reconstruct the shape of an input motion cuboid. As we stack the convolutional layers at the beginning of the network, we stack the deconvolutional layers to capture different levels of shape details for building an autoencoder. The filters in early layers of convolutional and the later layers of deconvolutional layers tend to capture specific motion signature of input video frames while high level motion abstractions are encoded in the filters in later layers.(这段话的用意在哪里)3.(4.3)这节都不知道在说啥…
A discriminative framework for anomaly detection in large videos
链接:code、python_code
来源:ECCV2016
创新点:异常的分数是独立于时间顺序的,不需要分开的训练序列。
2015
crowd motion monitoring using tracklet-based commotion measure
来源:ICIP2015
贡献:1.提出用Motion Pattern来在magnitude和orientation上表示每一帧的tracklet的statistics。2.提出Tracklet Binary Code representation在空间和时间上建模一个异常点在其对应轨迹上的运动。3.我们提出了一个新的unsupervised measure来评估像素、帧和视频层级的群体场景的commotion。
方法:1.tracklet extraction。先用SIFT算法检测异常点,再用跟踪的方法跟踪 L+1 帧。下图的(a)。
2.Motion Pattern。用空间坐标表示对应的异常点,进而计算magnitude和orientation。之后画出来binary polar histogram(只有0、1二值)。把经过vectorized polar histogram叫做motion pattern。下图的(b)。
3.Tracklet Binary Codes。把上一步的所有motion pattern连接起来计算一个tracklet histogram。H就是Tracklet Binary Codes。下图的(c)。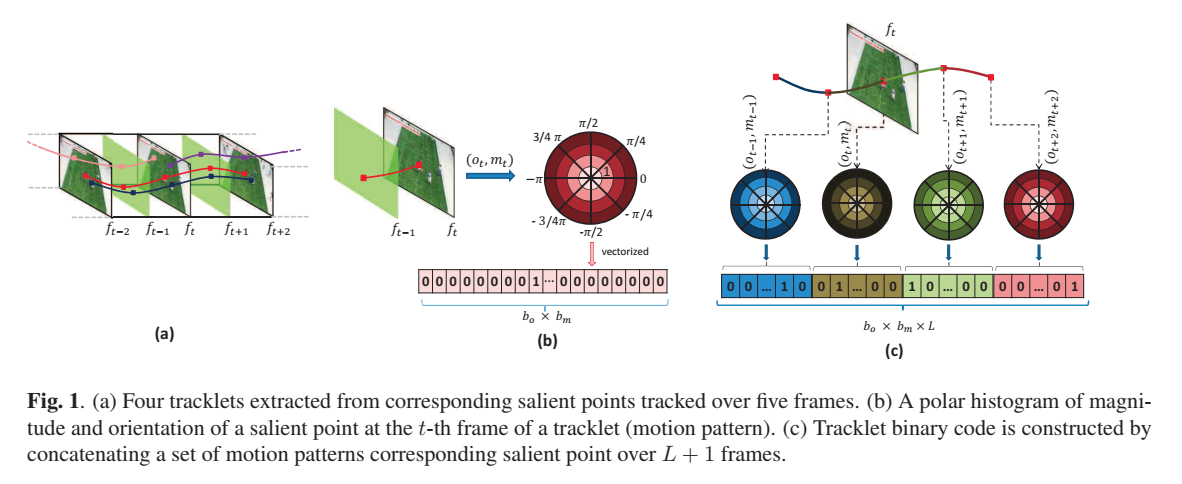
细节:在做frame-level的对比实验时,由于和比较的方法HOT(有监督的),没有直接的可比性,所以把视频序列分成了两个子集,A和B。训练和测试两遍,分别是A或者B训练,B或者A测试。和HOT相比,两种方法都比较好,但是我们的方法更好因为我们是无监督的。
疑惑的地方:2中的commotion measuring的那部分以及3中的video-level部分。
Video Anomaly Detection and Localization Using Hierarchical Feature Representation and Gaussian Process Regression
来源:CVPR2015
创新点:通过层级框架来检测局部和全局的异常,通过层级特征表示和GPR(高斯过程回归)。为了同时检测局部异常和全局异常,我们提出了从训练视频中提取normal interactions 的问题(??),即有效地找到附近稀疏时空兴趣点的频繁几何关系。用GPR建立并建模了interaction templates的codebook。另外提出了一个新的计算observed interaction的likelihood的inference方法。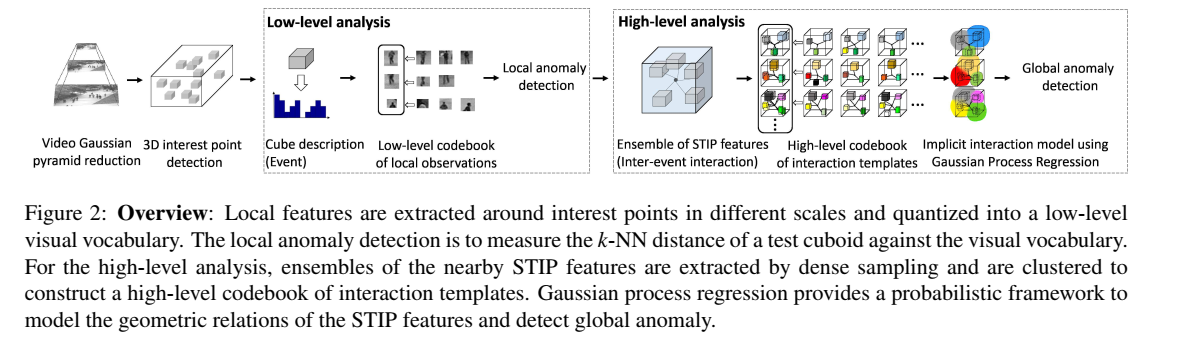
Learning Deep Representations of Appearance and Motion for Anomalous Event Detection
来源:BMVC2015
创新点:提出了Appearance and Motion DeepNet(AMDN)来自动学习特征表示。stacked denoising autoencoders用来分别学习外观和运动特征,以及联合表示。作者是第一个用无监督的深度学习框架来对视频异常检测自动construct discriminative representations 。设计了两次fusion。第一次叫做pixel-level early fusion,第二次叫做late fusion。
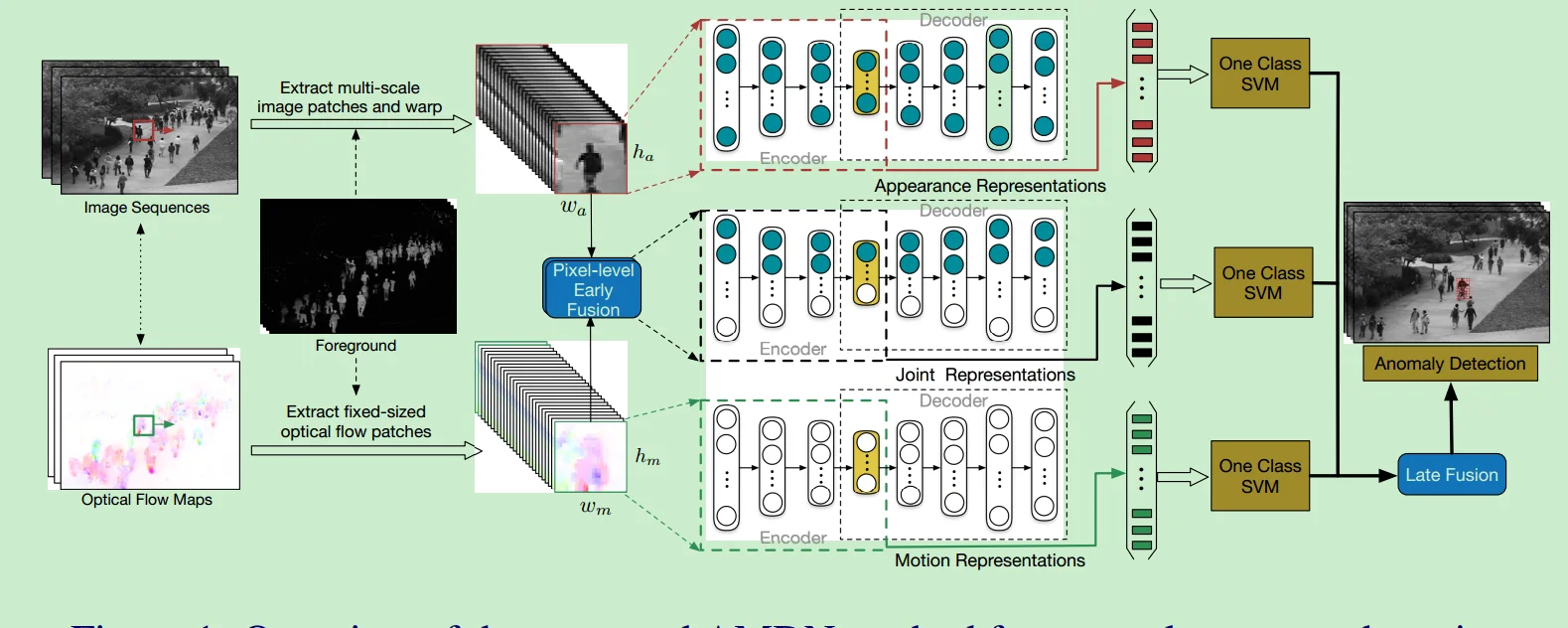
细节:1.训练AMDN用两个步骤,pretraining和fine-tuning。2.本文用了前景分割!
总结:简单来说,就是SDAE+one-class SVMs
疑惑的地方:2.2.1节 One-class SVM Modeling 2.2.2节 Late Fusion for Anomaly Detection
2014
Anomaly Detection and Localization in Crowded Scenes
来源:PAMI
考虑异常行为的检测和定位。提出了同时检测时空异常的detector。
Temporal normalcy用MDT(mixtures of dynamic textures)建模,spatial normalcy由基于MDT的一个discriminant saliency 检测器来检测。
考虑了外观和动态,时间和空间和多种空间规模。提出了USCD数据集。数据集的相关介绍可以看看这篇的6.1.这伙人在cvpr2010anomaly detection in crowded scenes出现过。
【就是同一篇论文吧。】
2013
abnormal event detection at 150 fps in matlab
来源:ICCV2013
里程碑:avenue数据集是他们弄的
引言:影响高效率的一个阻碍是建立稀疏表示的inherently intensive computation 。
优势:快~每秒140-150帧在平常的电脑上。有效地将原来的复杂问题转化为只涉及少量无代价的小尺度最小二乘优化步骤,从而保证了较短的运行时间。
方法:Sparse combination learning。和子空间聚类subspace clustering有关系但是又和传统的方法大不相同。子空间聚类的方法的聚类数量k是提前知道或者固定的,我们的方法用允许的表示误差来建立组合,误差上限是显式表现的,具有统计意义.
稀疏组合学习有两个目标:一是有效的表示,即找到K个基底组合,有较小的重建误差。二是让组合的总数K足够小。因为K大的话会让重建误差总是接近0,对于异常的事件也是这样。这两个目标是矛盾的。
训练的时候用了一个maximum representation的策略,自动寻找K但是不让重建误差大幅度增加。实际上对于每个训练特征的误差t都有一个上限。我们的方法以迭代的方式执行。在每个pass中,我们只更新一个组合,使它尽可能多地表示训练数据。这个过程可以快速找到编码重要和最常见特性的主要组合。不能很好地表示此组合的其余训练块特征将被送到下一轮以收集剩余的最大共性。
其他的方法:降低字典的大小【 Sparse reconstruction costs for abnormal event detection. In CVPR 2011】和采用快的稀疏编码solvers【 Online detection of unusual events in videos via dynamic sparse coding. In CVPR, 2011】,但是他们仍然不够快。
细节:每帧resize成3个不同的scale*(20x20,30x40,120x160),每种scale的frame分成很多小块(10x10的不重叠小块),一共是208个子块(4+12+1216=208),看图5就知道啦。之后连续5帧的对应的regions堆叠起来组成时空块对于时空快计算3D gradient features 和【 Anomaly detection in extremely crowded scenes using spatio-temporal motion pattern models.CVPR2009 】一样。这些特征在视频序列中是根据它们的空间坐标分别处理的。只有在视频帧中相同空间位置的特征才会被一起用于训练和测试。
稀疏组合的检验:一共150个不同的video,收集了一共208*150groups的cube features。每个group的组合数表示为K。如图4所示:组合数是10就足够用了。图5中很多region用1个组合就够了因为他们是静态的。

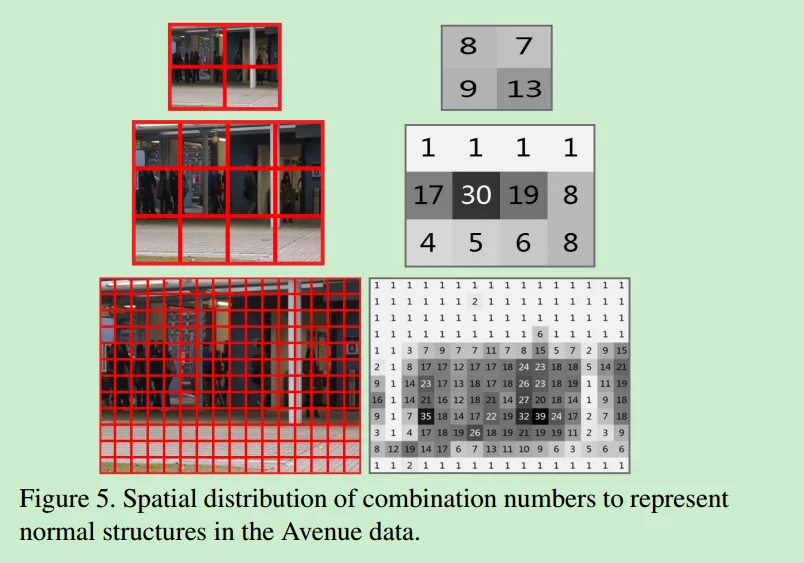
疑惑的地方:1. 2.3节update那里。2.table2和table3中的MISC是什么意思。
2011
Video Parsing for abnormality detection
来源:ICCV2011
创新点:Parse video frames by establishing a set of hypotheses that jointly explain all the foreground while, at same time, trying to find normal training samples that explain the hypotheses.
关键词:object hypotheses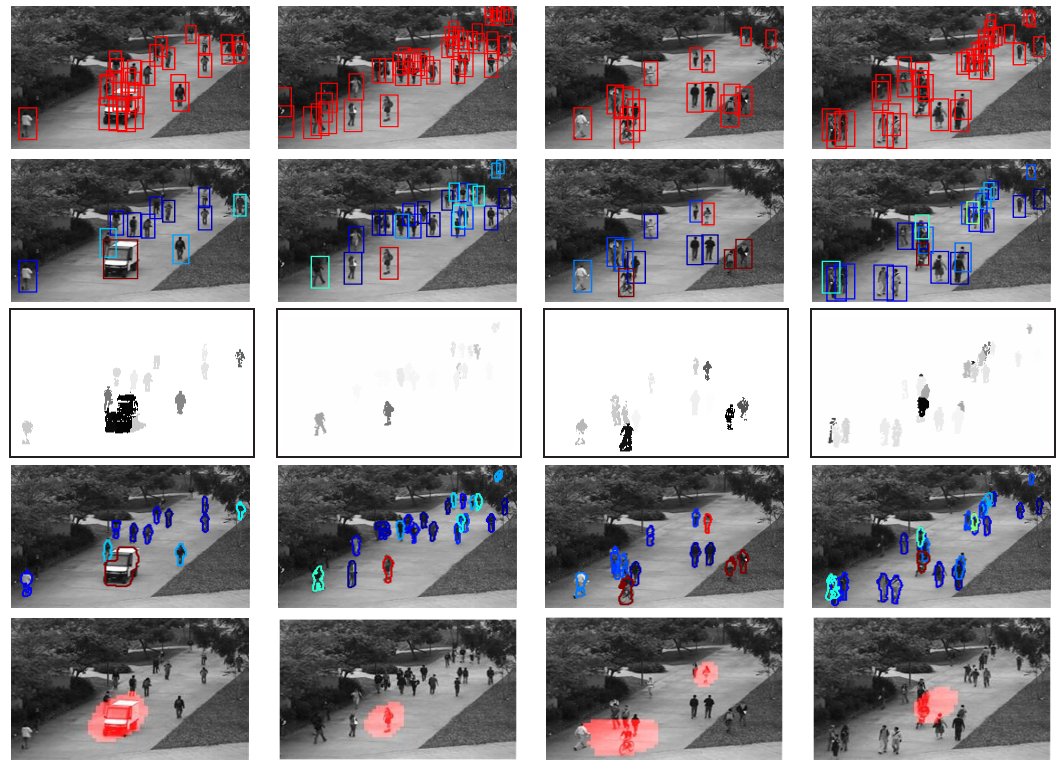
Sparse Reconstruction Cost for Abnormal Event Detection
来源:CVPR2011
摘要:引入了sparse reconstruction cost。我们的方法提供了一个unified solution来同时检测local abnormal events和global abnormal events。(什么是全局异常呢?就是整个场景是异常的,即使individual local behavior can be normal,什么是局部异常呢?就是local behavior is different from its spatio-temporal neighborhoods.)
引言:稀疏表示能够表示高维度的sample。
贡献: 1.support an efficient and robust dstimation of SRC
2.方便地处理LAE和GAE异常。
3.通过逐步更新字典,我们的方法能够支持在线的异常检测。
细节:USCD ped1 数据集处理方法——–把每帧分成了7x7的local patches,有4像素的重叠。用了Type C basis(spatio-temporal basis),dimension 7x16=102.
subway数据集处理方法———把帧从512x384大小resize成了320x240大小,并把新的视频帧分成了15x15local patches,有6像素的重叠,用了Type B basis(temporal basis),dimension 16x5=80??
方法: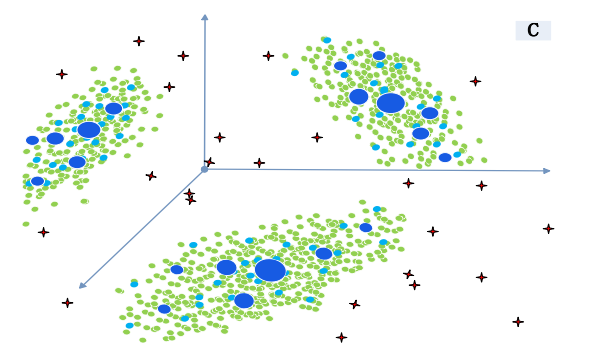
绿色或红色的点是正常或异常的测试样本。representatives(深蓝色的点)的optimal subset通过redundant training features(浅蓝色的点)作为basis来构成正常的字典。深蓝色点的半径表示权重,越大表示越正常。异常检测就是measure 测试样本(绿点或红点)在深蓝色点上的稀疏重建成本。
Online Detection of Unusual Events in Videos via Dynamic Sparse Coding
来源:CVPR2011
创新点:We propose a fully unsupervised dynamic sparse coding approach for detecting unusual events in videos based on online sparse reconstructibility of query signals from an atomically learned event dictionary, which forms a sparse coding bases.
误检的情况:Subway Exit数据集里面,出现了小孩误检为异常,一个人停在出口并且回头看也误检。
相比前人来说成功的地方:our method not only detects abnormalities in a fine scale, but also unusual events caused by irregular interactions between people
2010
Anomaly Detection in Crowded Scenes
来源:CVPR2010
MDT模型
时间异常检测:[23]背景帧差法。GMM MDT
空间异常检测:center surround saliency with the MDT
Chaotic invariants of lagrangian particle trajectories for anomaly detection in crowded scenes
来源:CVPR2010
特殊的粒子轨迹的应用
引入了chaotic dynamics
2009
Abnormal crowd behavior detection using social force model
来源:CVPR2009
社会力模型
Bag of words方法来分类异常和正常
这个方法比基于纯光流的方法好。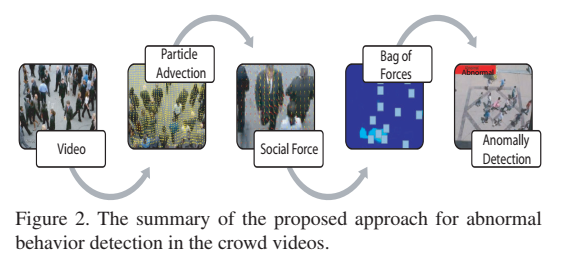
Observe Locally, Infer Globally: a Space-Time MRF for Detecting Abnormal Activities with Incremental Updates
来源:CVPR2009
创新点:提出了一个空时MRF模型。为了学习每个local node的正常行为模式,用Mixture of Probabilistic Principal Component Analyzers(MPPCA) 来capture光流的分布。另外,模型参数可以在新的观测进来的时候updated incrementally。
方法:We extract optical flow features at each frame, use MPPCA to identify the typical patterns, and construct a space-time MRF to enable inference at each local site.
作者说自己的优势:1.可以在local和global context检测异常活动。比单纯是local的方法好,local的方法fails to detect abnormal activities with irregular temporal orderings,并且local的方法对于光流参数很敏感导致高的false alarm rate.比单纯是global的方法好,global的方法fails to detect abnormal activity happens within a region so small,这个region在全局的场景中简单的被视为可以忽略的噪声。并且global的方法在拥挤的环境中会产生false alarm。
对前人的方法做了什么改进:用了08年Robust Real-Time Unusual Event Detection Using Multiple…的subway数据集的gt,但是capture 更微小的异常,比如“no payment”和“loitering”.
误检或者漏检的情况:entrance gate数据集中1.走的慢的人。2.对于far-filed area,产生了false alarm,因为光流对于far-filel area是不靠谱的。3.走的很快的人。4.没刷卡的人。exit gate数据集中”from right exit to left exit”
2008
Robust Real-Time Unusual Event Detection Using Multiple Fixed-Location Monitors
来源:PAMI
方法:local-monitors-based 。
通过multiple, local, low-level feature monitors来监视不寻常的事件。每个monitor是从视频流提取local low-level observation的object。这个observation可以是在monitor的位置的现在的光流方向,或者是local flow的magnitude。
异常检测需要什么:1.对于给定的视频流的tuning 算法应该简单快速。2.算法应该adaptive,适应环境的变换。3.short learning period。4.低成本。5.predictable performance。
局限性:不能检测loitering person或者在进入安检的时候不刷卡。总结里面说,局限性是the lack of sequential monitoring.
术语:aperture problem孔径问题https://blog.csdn.net/hankai1024/article/details/23433157;SSD error matrix
评价:2009年Observe Locally, Infer Globally: a Space-Time MRF for Detecting Abnormal Activities with Incremental Updates评价:focus attention on individual local activities,where typical flow directions and speeds are measured on a grid in the video frame. While efficient and simple to implement, such an approach fails to model temporal relationships between motions.
思考:为什么作者用了这个方法,有什么优缺点。